Research Radar: explainable discovery for MIR and audio ML papers
Research Radar is a research-discovery prototype for music information retrieval and audio ML papers. I built it to make recommendations easier to understand: you can browse ranked feeds, open a paper, explore trends, and compare the output against simpler baselines.
The live app stays separate from this portfolio, and the experimental parts are labeled honestly. Bridge recommendations are still exploratory, and the evaluation view is there to show how the system behaves, not to claim the ranking problem is solved.
The live prototype is meant to stay deployed separately from this portfolio. Once its public URL is pinned, this page can link out to it directly.
Portfolio-side overview of the current prototype surfaces and product framing. This is an architecture-style summary, not a literal app screenshot.
Ranked recommendations
Visitors can browse emerging papers, undercited papers, and an experimental bridge view. Each list is generated ahead of time and includes enough detail to show why a paper was recommended.
Paper detail with similar papers
Each paper page shows metadata plus a related-papers section, so someone can move from one useful paper to the next without starting over from search every time.
Trends in the current dataset
The trends page gives a quick read on which topics are gaining momentum in the current dataset, without pretending to summarize the whole field.
Evaluation as transparency
The evaluation page compares the ranking against simpler baselines like citation count and recency. That makes it easier to inspect how the system behaves without pretending there is one perfect relevance score.
Engineering choices, in plain language
Recommendations should answer "why is this here?"
The app keeps a saved record of how each ranked list was built and which signals fed into it, like showing your work instead of just giving a final answer. That makes the system easier to debug, easier to compare across versions, and easier to explain to another person.
Splitting the site from the prototype is intentional
This page is the case study, while the prototype runs as its own app. Under the hood there is a Next.js frontend, a FastAPI backend, Postgres with pgvector for storage and similarity search, and Python jobs for ingest, ranking, and clustering. Keeping those pieces separate makes it easier to update the ranking workflow without turning every change into a full-site deploy.
Experimental ideas stay visible and clearly bounded
Some ideas are still exploratory, especially bridge-style recommendations that try to connect papers across areas. I left them visible because they are real product work, but they are not positioned as finished or used as the default experience.
Visual walkthrough
These captures were taken from a recent run of the prototype against the current API. I pinned the ranking and embedding versions so this walkthrough reflects a real, reproducible state rather than a mocked-up demo: ranking version ml2-5a-qual-r2-k6-20260405 and embedding version v1-title-abstract-1536-cleantext-r2. The app stays deployed separately from the portfolio; this section shows what the live prototype looked like at that pin.
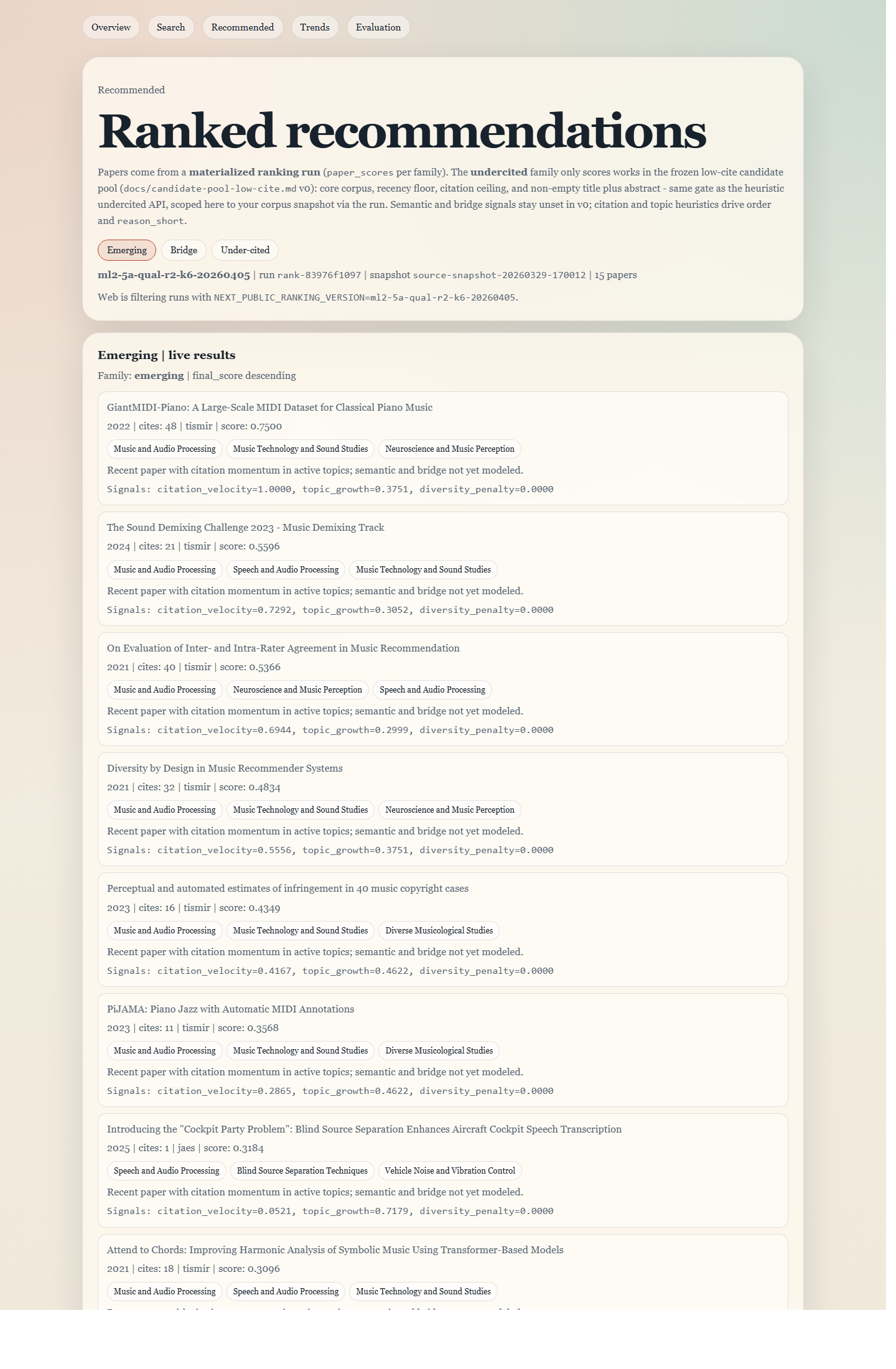
Recommended: emerging
/recommended?family=emerging
The clearest introduction to the product: a ranked list with visible recommendation signals.
Evaluation
/evaluation?family=emerging
Shows the project's honesty. The ranking is compared against simpler baselines instead of being presented as unquestionable.
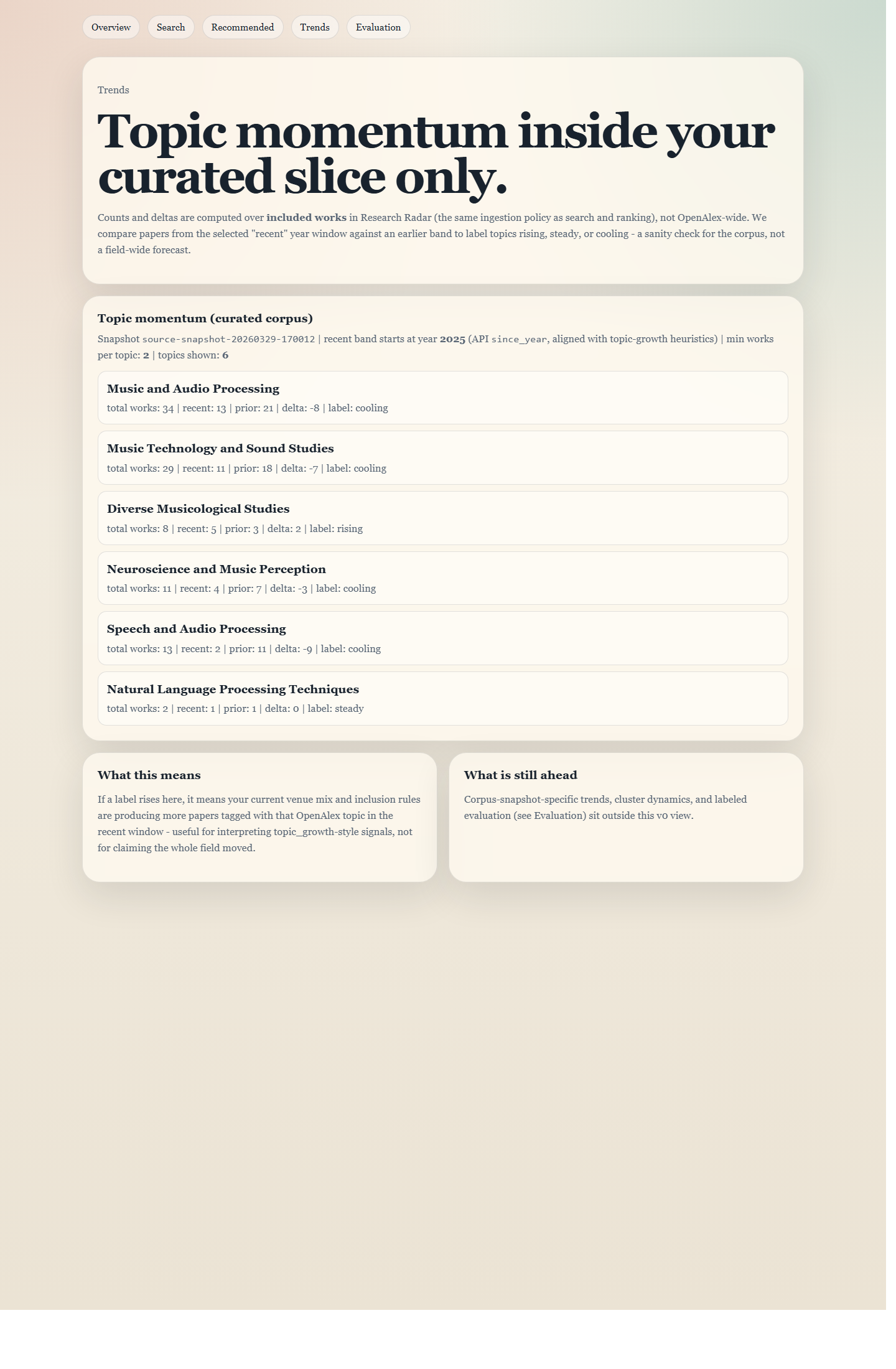
Trends
/trends
Shows that the prototype is not only a recommendation feed; it also gives a quick view of topic momentum in the dataset.
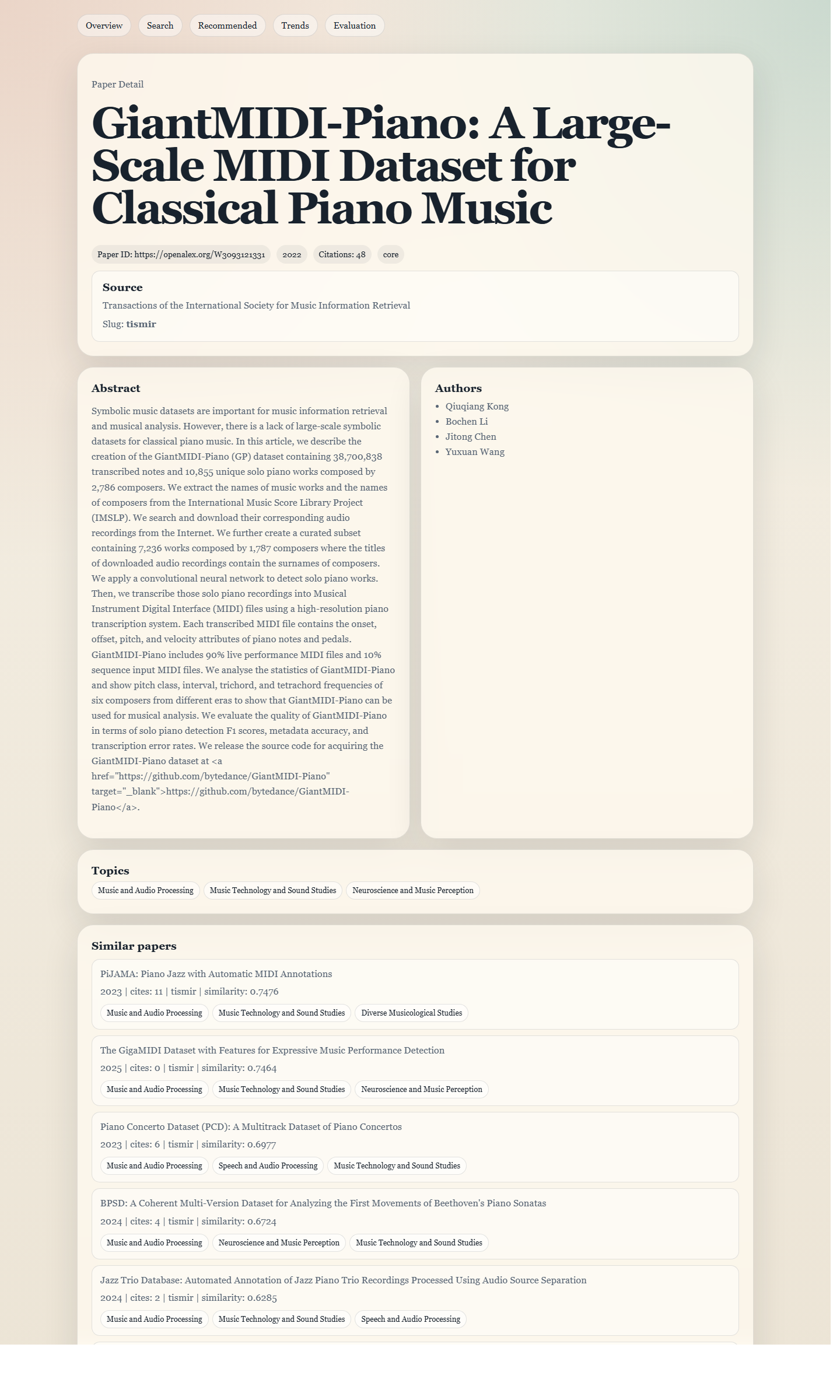
Paper detail with similar papers
/papers/https%3A%2F%2Fopenalex.org%2FW3093121331
Shows how someone can move from one paper into a useful cluster of related work.
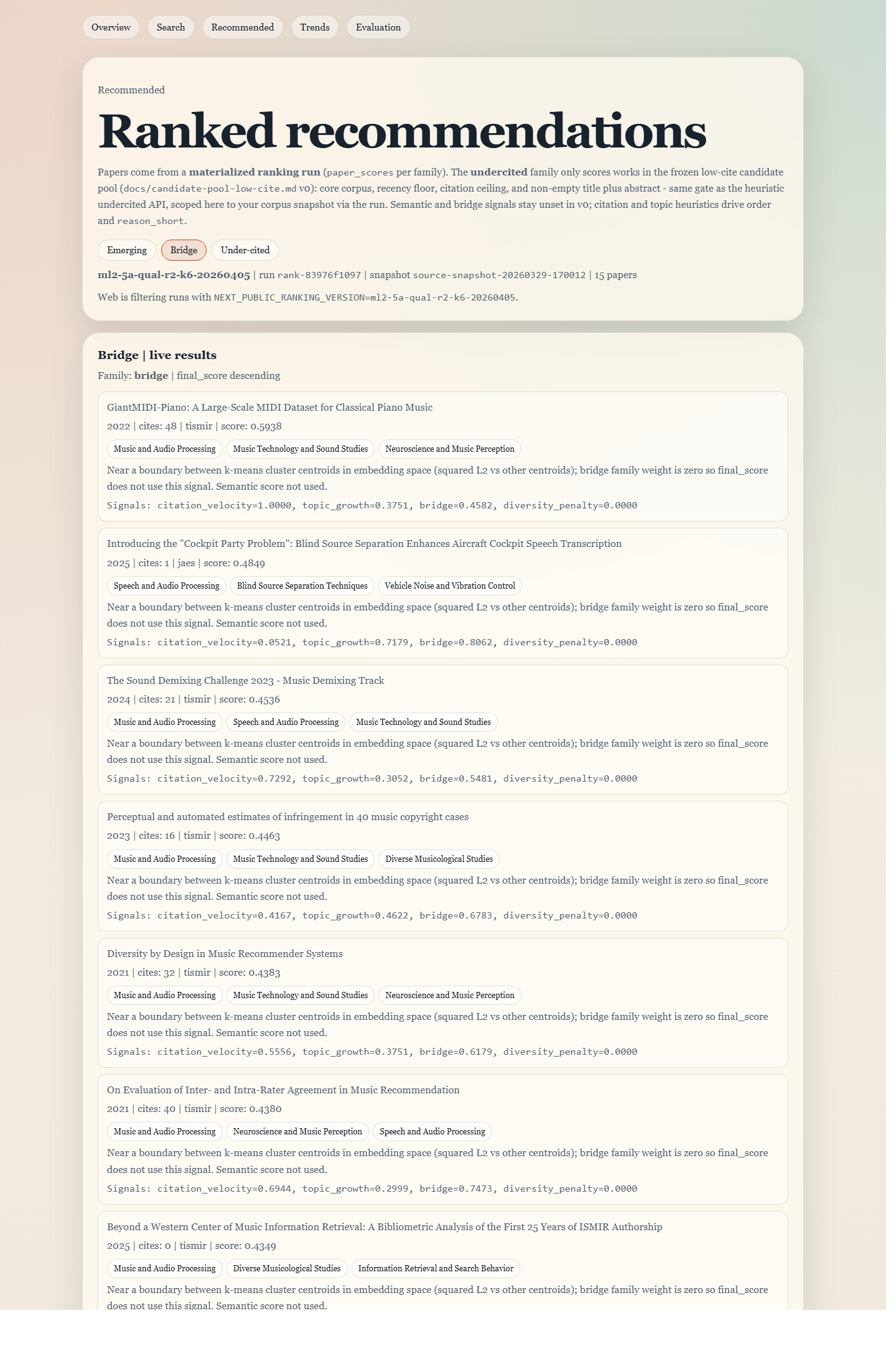
Bridge family (experimental)
/recommended?family=bridge
An honest look at the experimental bridge view, which is still exploratory rather than a finished recommendation mode.
Stable now
The main product is a set of ranked paper feeds that show why items appear where they do.
Paper detail, trends, and evaluation are all working parts of the prototype.
The strongest current value is helping someone inspect and compare recommendations, not hiding the ranking logic.
Experimental notes
Bridge recommendations are still experimental, not a mature standalone feature.
I tested weighted variations, but the current setup did not produce a meaningfully different bridge list.
The next step is likely better bridge signals and tighter filtering, not simply increasing the current weight.
Boundaries
Semantic ranking is not part of the default ranking today.
Bridge stays off by default in production.
The corpus is still curated and narrower than the long-term vision.
Tech stack
The interface is built in Next.js, the API is built in FastAPI, and the data lives in Postgres with pgvector. A separate Python pipeline handles ingest, cleanup, embeddings, ranking, and clustering experiments behind the scenes.
The strongest stable claim today is that the prototype makes its ranking behavior visible and understandable over a curated set of MIR and audio ML papers.
Known limits: Bridge recommendations are still experimental, semantic ranking is not part of the default ranking, and the corpus is still narrower than the long-term plan.
Leave a question or comment
No questions or comments yet. Sign in with GitHub to leave the first one.